

A monitor in mission control shows the time remaining as Cassini made its final plunge into Saturn in September. Image: Joel Kowsky/NASA
Spare a thought for the team of data scientists at NASA, which arguably has the toughest job in the business when it comes to managing data.

We hear an awful lot about how data is the ‘oil’ of a new generation, the lifeblood of countless industries that will use what we generate through our phones, planes and automobiles to their benefit.
So, bear in mind how much data is being generated by an agency whose remit not only covers everything here on Earth, but everything we can see in the known universe.
That’s the job of NASA, one of the biggest generators of data gatherers and distributors in the world on everything from the latest climate data to – as we saw quite recently – the hidden secrets of our solar system’s ringed planet, Saturn.
The numbers
To get a sense of just how much data is generated, Siliconrepublic.com spoke to Kevin Murphy, NASA’s Earth science data systems programme executive who, quite frankly, blew this journalist’s mind.
According to Murphy, as recently as last year, NASA was generating 12.1TB of data every single day from thousands of sensors and systems dotted across the world and space.
As NASA upgrades its spacecraft to handle much faster and larger data transmissions by a factor of 1,000 using optical lasers, the expectation is that some missions could generate as much as 24TB in a single day.
All of this is then added to an archive that contains an estimated 24PB, or 24,000,000GB, pushing it to the point where trying to equate that to everyday examples of data storage in your life becomes impossible.
But it doesn’t stop there. Murphy added that within the next five years, NASA expects this archive to more than double to 50PB as it launches new missions to analyse Earth and other planets.
By comparison, the amount of data the US Postal Service sends via letters every year amounts to approximately 5PB.
How does NASA keep on top of all this data?
It starts, Murphy said, as any IT department would, in that the amount of data expected to be generated is estimated and planned accordingly, but he does admit that it is still a “big job”.
To store it, NASA has adopted a pretty diverse system, with both an established commercial cloud platform sourced from the likes of Google and Amazon, and its own data centres.
The space agency is currently in the midst of pruning the number of data centres it operates, with 33 out of 59 closing as it attempts to beat the 2018 deadline set out by the US government requiring federal services to optimise and downsize their data centre square footage.
Unlike other federal agencies, however, NASA’s data centres are shared between those with a scientific discipline expertise and those with a data management background.
Also unlike pretty much any agency of its size – looking particularly at entities such as the NSA and CIA – NASA has to make everything it does public, and that means absolutely everything.
“We have a data policy that is full, free and open, not only in the data products, but the algorithms used to generate that data as well as calibration information, which is very important for scientific work,” Murphy said.
Last year, 3.2m people accessed NASA’s databases and downloaded scientific data for their research, which means the agency’s systems need to be easily accessible to everyone at any given moment.
Perhaps the greatest example of this is OpenNASA, its catalogue of more than 32,000 datasets and more than 50 APIs available for anyone to download and tinker with.
“Having to scale our systems to meet the demands of that many users poses its own unique challenges,” Murphy added.
“When we build these systems to accommodate millions of users per year, we have to be very cautious about what services we generate to ensure that they’re robust enough to work at those scales.”
Meet Nadia Chilmonik, navigating the world using data, creativity & self-organizing maps: https://t.co/jNPizeGGnG #NASADatanauts #NASAsocial pic.twitter.com/fhDZeZFSvJ
— openNASA (@openNASA) September 22, 2017
AI has a role to play
Within NASA however, there remains questions over how it plans to handle annual data growth of between five and 10PB per year. For Murphy and his colleagues, artificial intelligence (AI) and machine learning will play a key part.
With the example of hurricanes or other environmental data that he works with, given his responsibility with data generated by NASA’s activities on Earth, AI will be necessary to help human scientists find the correct data sources and point them in the right direction to join up the dots with previous research.
“When people are looking at science data, they’re looking for anomalies and characteristics that fall out of statistical families. I think AI and machine learning can certainly help in those areas,” Murphy said.
Last June, NASA’s principal data scientist with the Jet Propulsion Laboratory’s machine learning group, Kiri Wagstaff, touched on this when she said that AI will be integral to the space agency’s spacecraft figuring out scientific problems for themselves.
“We don’t want to miss something just because we didn’t know to look for it,” she said. “We want the spacecraft to know what we expect to see and recognise when it observes something different.”
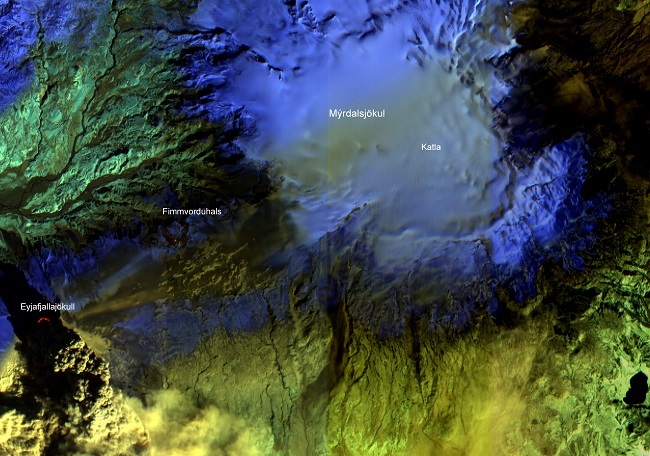
AI on board a NASA Earth science satellite detected the eruption of an Icelandic volcano in 2010, resulting in this picture. Image: NASA/JPL/EO-1 Mission/GSFC/Ashley Davies
However, trying to integrate machine learning and open data on a grand scale will prove to be NASA’s greatest challenge from a data science perspective, according to Murphy.
“We’ve typically had a paradigm where someone comes in and downloads our products but, as volumes that are already very large increase to even larger amounts, it’s going to be more difficult to scale the systems, especially the distribution systems, to meet the needs of that community.”
One answer, he added, will involve getting scientists to teach the next generation of graduates across the globe on how to process data more easily, using ever-advancing technologies such as quantum computing and cloud computing.
Thankfully for NASA, the future looks a bit brighter, with former US president Barack Obama announcing the Big Data Research and Development Initiative in 2012 to make agencies such as NASA more capable of handling massive amounts of data.
At the moment, it feels as if NASA is taking one small step for data and one giant leap for humankind.





